들어가기 앞서

이제 리스트들을 거쳐서 Stack으로 왔어요.
스택은 리스트보다 이해가 잘 될 것이라고 생각합니다.
노드를 포인터를 이용하여 연결하는 것이 기억안난다면? 혹은 기초적인 것이 기억이 안난다묜?
연결 리스트를 봐주시길 바라요.
첨쓴거라 젤 열심히 씀
연결 리스트(Linked List), C언어 구현, 코드(너 ㅋ 이해하고 싶어?)
들어가기 앞서 Linked List 즉 연결 리스트는, C언어를 사용한 자료 구조중에서도 가장 기초라고 생각합니다.이 아무것도 보르는 바보 C언어(C99)를 사용하여 백준을 풀때 가장 많이 사용했었쥬..
8ehrmin.tistory.com
스택
동적이고 순차적인 자료의 목록. 시스템의 기억 장치에 설치하며 한쪽 끝에서만 저장과 제거를 할 수 있는 특성이 있다 (네이버)
LIFO 및 FIFO 구조를 가지는 자료구조 (내가씀)
stack은 가장 마지막에 들어간 데이터가 가장 먼저 나오고(LIFO : Last In-First Out),
가장 먼저 들어간 데이터는 가장 나중에 나오는(FILO First In-Last Out) 자료구조입니다.
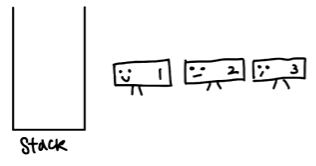
어머나 stack이라는 방 안에 가고싶은 자료들이 있나봅니다.
1, 2, 3은 순서대로 들어가고 싶어서 차례를 기다립니다.
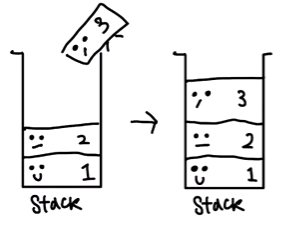
순서대로 PUSH 해 보니, 1이 가장 밑에 그리고 3이 가장 위에 있는 구조가 되었습니다.
이제 너무 껴보이네요.
stack이라는 병은, 입구와 출구가 같아서 나갈 때 는, 3->2->1로 나가야 합니다. 얼른 POP즉 나가게 해볼까요?
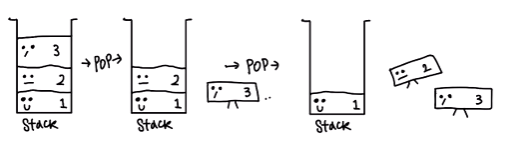
처음 들어왔던 1번은 가장 늦게 나가게 되는 구조네요.
왜냐하면?!? 입구와 출구가 1개 이기 때문입니다.
쌓여있으니 어쩔 수 없죠?
따라서 이러한 구조를 LIFO, FILO이라고 합니다.
또한 자료구조가 들락날락 하는데 있어서 필요한 기능은? 보니까 POP과 PUSH밖에 없는 것 같네요!
리스트와는 다르게 단순한 것 같죠?
스택어디서 씀?
stack은 정말 흔한 곳 에서 볼 수 있는데요.
가장 많이 본 곳은 프로세스의 stack이라고 볼 수 있습니다.
함수를 예로 들어볼까요?
void stack3()
{
printf("stack[3] PUSH\n");
printf("stack[3] POP\n");
}
void stack2()
{
printf("stack[2] PUSH\n");
stack3();
printf("stack[2] : POP\n");
}
void stack1()
{
printf("stack[1] : PUSH\n");
stack2();
printf("stack[1] : POP\n");
}
void main()
{
stack1();
}
결과는 어떻게 나올까요?
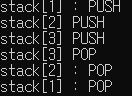
그림으로 main에서 stack을 보겠습니다.
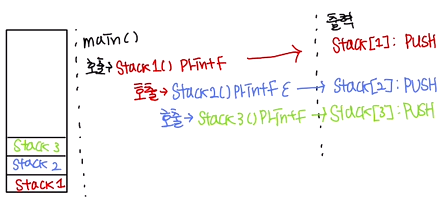
이제 호출은 곧 PUSH이니, 모든 코드를 수행했다면 탈출 즉 POP을 해야겠죠?
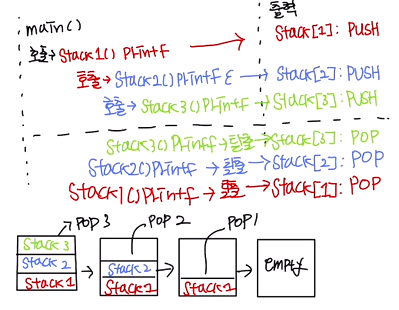
이렇게 함수는 스택구조로 실행됩니다.
(넘 대충 그렸삼)
이제 스택을 코드로 보겠습니다.
배열 기반 스택 노드
먼저 배열 기반으로 스택을 구현할 것 입니다.
배열로 스택을 구현했을 때, 구현은 간단하지만 동적으로 스택 용량을 변경하는 경우 코스트가 크다는 단점이 있습니다.
하지만서도 여러 예제를 기반으로 배워야 이해도 가고 슥슥 코드를 작성할 수 있겠죠?
typedef int elementType;
typedef struct tagNode
{
elementType data;
}Node;
typedef struct tagArrayStack
{
int capacity;
int top;
Node* node;
}arrayStack;먼저 tagNode는 스택 안에 들어가는 자료로 보면 됩니다.
리스트에서 사용하던 노드와는 달리 이전 혹은 다음 노드를 알 필요는 없습니다.
배열을 기반으로 하기 때문에 인덱스를 이용하여 노드를 사용할 수 있기 때문이죠.
typedef int elementType;
typedef struct tagNode
{
elementType data;
}Node;담은 tagArrayStack입니다.
배열이 될 구조체입니다.
구조체의 필드를 각각 보겠습니다.
int capacity : 배열의 용량을 알기위한 필드 ( 배열의 크기를 알 수 있다 )
int top : 최상위 노드의 위치를 알기위한 필드 ( 배열의 삽입 및 삭제를 편리하게 하기 위하여 사용 한다 )
Node* node : 스택에 쌓이는 노드를 보관하기 위한 필드
stack은 POP과 PUSH연산만으로 자료구조를 이용할 수 있습니다.
POP이 되는 요소는 가장 위에있는 요소 밖에 없겠죠?
PUSH가 되기 위하여 누구 다음인지 알기 위한 요소는 가장 위에 있는 요소 밖에 없겠죠?
따라서 삽입 삭제에 용이하기 위해 top이라는 필드가 필요합니다.
Node 포인터는 단순히 Heap에 노드들을 순차적으로 메모리를 할당하여 사용하기 위한 필드입니다.
typedef struct tagArrayStack
{
int capacity;
int top;
Node* node;
}arrayStack;스택 노드 생성 및 소멸
스택 노드에 동적으로 메모리를 할당하며 생성하기 위한 연산이 필요할 것 입니다.
또한 동적으로 메모리를 할당했다면?
개발자는 책임지고 이를 해제해야 하죠.
그에 대한 설명입니다.
(추가적인 설명이 필요하다면 이전 게시물을 참고하고 와주세여)
void createStack(arrayStack** stack, int capacity)
{
(*stack) = (arrayStack*)malloc(sizeof(arrayStack));
(*stack)->nodes = (Node*)malloc(sizeof(Node) * capacity);
(*stack)->capacity = capacity;
(*stack)->top = -1;
}
void destroyStack(arrayStack* stack)
{
free(stack->nodes);
free(stack);
}
malloc함수를 사용하여 동적 메모리를 할당하는 것을 볼 수 있습니다.
stack구조체의 필드를 각각 채워주는 부분에서, top이 -1인 이유는 해당 arrayStack이 비었다는 것을 의미합니다.
왜냐하면 일반적인 배열의 인덱스를 생각해 봅시다.
0부터 항상 시작하죠? 따라서 top이 0인 경우는 0번째 인덱스를 의미하는 것과 혼동할 수 있습니다.
그러므로 top을 -1로 초기화 해줌으로써 empty 배열임을 명시해 줍니다.
(*stack)->capacity = capacity;
(*stack)->top = -1;노드 삽입 연산
노드를 삽입하는 방법은, 간단합니다. 코드를 먼저 보겠습니다.
void pushNode(arrayStack* stack, elementType data)
{
stack->top++;
stack->nodes[stack->top].data = data;
}
스택의 탑을 높이고, 노드 배열의 데이터를 넣어라 라는 2줄짜리 코드입니다.
예시로 기존에 top이 2였고, 들어온 data의 값이 3이었다면
1. top++ : top이 ++ 됨으로써 top은 3이 될 것 입니다.
2. 노드배열의 3번째 인덱스에 data(3)을 넣는 코드입니다.
즉
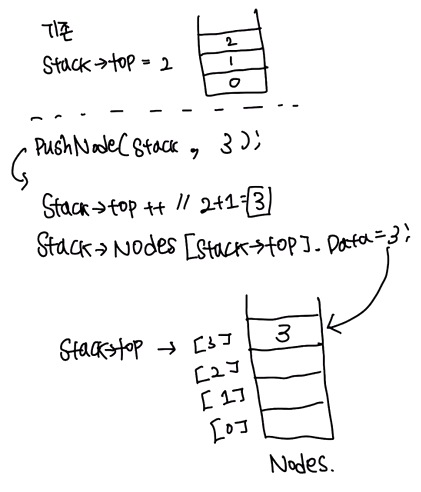
위와같이 나타낼 수 있습니다.
노드 제거 연산
노드 제거 연산은, 기존 리스트에서의 제거와 비슷하지만, POP이 되면서 제거된 데이터를 사용자에게 반환해야합니다.
따라서 제거를 함과 동시에 제거한 노드의 데이터를 반환해주는 코드를 작성하면 됩니다.
elementType popNode(arrayStack* stack)
{
int position = stack->top--;
return stack->nodes[position].data;
}기존 top의 정수를 position 변수로 받아줌과 동시에 top을 -1처리 해줍니다.
또한 이전 top의 data값을 반환해주며 함수는 마무리됩니다.
배열 기반 스택 예제 프로그램
지금까지 배운 연산을 모두 활용할 수 있는 프로그램을 작성해 보겠습니다.
#include<stdio.h>
#include<stdlib.h>
#pragma warning(disable:4996)
void printfBar()
{
printf("================================================================\n");
}
typedef int elementType;
typedef struct tagNode
{
elementType data;
}Node;
typedef struct tagArrayStack
{
int capacity;
int top;
Node* nodes;
}arrayStack;
void createStack(arrayStack** stack, int capacity)
{
(*stack) = (arrayStack*)malloc(sizeof(arrayStack));
(*stack)->nodes = (Node*)malloc(sizeof(Node) * capacity);
(*stack)->capacity = capacity;
(*stack)->top = -1;
}
void destroyStack(arrayStack* stack)
{
free(stack->nodes);
free(stack);
}
void pushNode(arrayStack* stack, elementType data)
{
stack->top++;
stack->nodes[stack->top].data = data;
printf("PUSH data : %d\n", stack->nodes[stack->top].data);
}
int isEmpty(arrayStack* stack)
{
if (stack->top == -1)
{
return 1;
}
else
{
return 0;
}
}
int isFull(arrayStack* stack)
{
if (stack->top == stack->capacity - 1)
{
return 1;
}
else
{
return 0;
}
}
elementType popNode(arrayStack* stack)
{
int position = stack->top--;
return stack->nodes[position].data;
}
elementType getTop(arrayStack* stack)
{
return stack->nodes[stack->top].data;
}
int getCount(arrayStack* stack)
{
return stack->top + 1;
}
void main()
{
arrayStack* stack = NULL;
printfBar();
printf("stack을 생성합니다.\n");
createStack(&stack, 5);
printfBar();
printf("stack요소를 PUSH합니다.....\n");
int capacity = stack->capacity;
for (int i = 0; i < 7; i++)
{
if (!isFull(stack)) pushNode(stack, i + 1);
else printf("[%d] error : stack is full\n", i + 1);
}
printfBar();
printf("stack요소의 TOP의 데이터를 출력합니다.....\n");
printf("Top : 인덱스[%d] : %d\n", stack->top, getTop(stack));
printfBar();
printf("stack요소를 POP합니다.....\n");
for (int i = 0; i < 7; i++)
{
if (!isEmpty(stack)) printf("POP data : %d\n", popNode(stack));
else printf("[%d] error : stack is empty\n", i + 1);
}
printfBar();
printf("stack을 해제합니다.\n");
destroyStack(stack);
}
어지럽네여.. 하하
끝으로
틀린 점이 있다면 알려주세요
이해 안가는 부분이 있다면 장문으로 물어도 좋으니 언제든 물어봐주시길 바랍니다.
참고
이것이 자료구조 알고리즘이다 with C언어
'자료구조' 카테고리의 다른 글
| 후위 표기법 변환, 다익스트라(Dijkstra) 알고리즘, c언어 구현 코드, postfix, infix 계산기, 자료구조 (0) | 2024.11.20 |
|---|---|
| 스택(Stack), c언어 구현 코드, 연결 리스트 기반 스택, 자료구조 (0) | 2024.11.18 |
| 환형 연결 리스트(Circular Licked List), 원형 연결 리스트, C언어 구현, 코드 부에궹ㄱ (1) | 2024.11.17 |
| 이중 연결 리스트(Double Linked List), C언어 구현, 코드 (0) | 2024.11.17 |
| 연결 리스트(Linked List), C언어 구현, 코드(너 ㅋ 이해하고 싶어?) (3) | 2024.11.15 |



