
들어가기 앞서
Linked List 즉 연결 리스트는, C언어를 사용한 자료 구조중에서도 가장 기초라고 생각합니다.
이 아무것도 보르는 바보 C언어(C99)를 사용하여 백준을 풀때 가장 많이 사용했었쥬..
만약 C언어를 수박 스윽 겉핥기로만 공부하셨다면 이해하는데에 시간이 걸렸을 거라고 생각합니다.
오늘은 그림을 보면서 어떻게 연결되는지 머리로 이해하는 시간을 가져보도록 할게요.
Liked List (연결 리스트) 란?
위키 백과 :데이터의 순서가 정해지지 않은 선형 집합
네이버 :기억 장소 내에 분산되어 있는 데이터 요소들을 관리하기 위하여 데이터 요소 내에 다음 데이터 요소의 위치에 관한 정보가 하나의 항목으로 포함되어 있는 리스트.
이것이 자료구조+알고리즘이다 : 노드를 연결해서 만든 리스트
사실 하나하나 보면 쉽죠?
연결 : 연결되어있다요
리스트 : 목록형태로 나열되어있다요.
이렇게 생각하면 정말 쉬울 것 이라고 생각합니다.
List vs Linked list
아니 ㅋㅋ 걍 배열(리스트)쓰면 되지 왜 연결 리스트씀? -> 이럴 수 있는데,
특정 상황에서 파이썬이나 자바는 리스트를 만들기 위해서 크기를 구체적으로 명시하지 않아도 됩니다.
벗버러벗벗벗(BUT), C언어는 배열을 초기화 할 때 어떻게 했죠?
int IamArr[10];
바로 크기를 지정해 주어야 합니다.
코드를 보면, C언어에서 정적으로 할당하는 방식이기 때문에 10을 상수로 두지 않는다면? 오류가 나버리죠.
즉 이는 10개라는 한정된 데이터만 수용할 수 있는 배열을 의미합니다.
그럼 10개는 작으니 마음 편하게 10,000개의 데이터를 수용할 수 있는 배열을 선언 해 볼까요?
int IamArr[10000];와우 겁나게 많은 데이터를 수용할 수 있겠어요.
하지만, 10000을 전부사용하지 않는다면?

프로세스가 이렇게 유연하다면, 살이 찔 수 있겠지만..
실상은 유연하지 않은 근육쟁이 프로세스이기 때문에, 다른 데이터를 수용할 수 없게 됩니다.
또한, 너무 많은 메모리를 할당 받았으면서, 사용하지 않으면 필요없게 되겠죠?
그렇다보니 정적으로 메모리를 할당하기 보다 사용할 만큼 동적으로 할당하여 사용하는 것이 두곽됩니다.
Linked List(연결 리스트)
그럼 연결리스트.. 너.. 어떻게 생겨먹은 자료구조인지 알아볼 필요가 있죠?

멀리서 보게 된다면, 연결고리(포인터)로 연결된 노드들로 보입니다.
그럼 노드를 좀 더 자세히 볼까요?

어머나 자세히보니 Filed와 Tag로 나뉘는 것을 볼 수 있습니다.
Node {
Filed : 데이터를 보관
Tag : 연결된 다른 노드의 Pointer 정보
}
이렇게 연결되어있는 노드의 포인터 정보를 구조로 가지고 있으니, 삽입, 삭제, 수정에 용이하게 됩니다.
포인터 정보를 수정하면 끝이니까요!
얘네도 위계질서가 잡혀있는데, 첫번째 노드 Head와 마지막 노드 Tail 그리고 그냥 노드로 구분할 수 있습니다.

Linked List Node Code
이제 추상적인 개념을 이해했다면, 실질적인 코드로 볼까요
Node
typedef int elementType;
typedef struct tagNode
{
elementType data;
struct tagNode* nextNode;
} Node;아 귀엽던 노드들이 재미없어 졌어요.
처음 코드부터 볼까요?
typedef int elementType;노드의 필드에는 데이터가 들어간다고 하였습니다.
이 데이터의 자료형은 필요에 따라 달라지겠죠?
따라서 현재 예시를 위한 데이터로는 int 타입의 데이터를 필드에 담는다! 라고 지정한 것 입니다.
typedef struct tagNode
{
elementType data;
struct tagNode* nextNode;
} Node;노드를 구조체로 선언한 후,
필드에는 elemenType의 Data를,
tag부분 즉 다음 노드의 포인터를 담았습니다.
Node의 생성과 소멸
Linked List를 만들기 위해서 노드를 만들어야겠죠?
또한, 저희는 동적 메모리를 할당하여 받아 사용하기 때문에 이를 해제할 책임도 있습니다.
따라서 생성과 소멸 코드를 볼게요.
Node의 탄생
Node* createNode(elementType newData)
{
Node* newNode = (Node*)malloc(sizeof(Node));
newNode->data = newData;
newNode->nextNode = NULL;
return newNode;
}노드의 탄생 과정을 보겠습니다.
먼저 목적을 생각해 봅시다.
사람들의 나이를 수집하는 예시를 둘까요?
그럼 데이터 필드에는 사람의 나이가 들어가게 될 것 입니다.
따라서 노드 탄생 함수에(createNode), 사람 나이가 데이터 필드에 해당하는 값이기 때문에 매개변수로 들어가게 됩니다.
Node* createNode(elementType newData)
{ . . . }
사람 나이가 들어갈 노드가 먼저 생성이 되어야 겠죠?
따라서 동적으로 메모리를 할당하는 함수(malloc)을 사용하여 노드를 생성하는 코드가 필요합니다.
Node* newNode = (Node*)malloc(sizeof(Node));이제 노드의 필드와 태그를 채워야 합니다.
newNode->data = newData;
newNode->nextNode = NULL;
여기서 Arrow(->)를 사용하는 이유는, 저희가 직접적으로 데이터를 우겨넣는 것이 아닌 포인터로 참조해서 데이터를 저장하기 때문입니다.
또한 nextNode가 현재 NULL인 이유도 생각해 봅시다.
이 노드가 생성은 됐지만, 현재 누가 옆에있는지 누굴 따라야하는지 모르는 상태 즉 애기 노드이기 때문입니다.
그렇다면 추후에 nextNode를 삽입해야 하는 과정이 필요하겠죠?
이거까지 촤악 추리(및 의심)하고 가면! 생성 과정은 여기서 끝입니다.
Node의 소멸
void destroyNode(Node* node)
{
free(node);
}동적 메모리를 해제하는 함수 free를 써주면 오케이 끝입니다. 헿
Node 추가 연산
지금까지 Node를 낑차낑차 만들어서 뿅~ 애기 노드가 태어나게 되었습니다.
그럼 이 애기 노드를 기존에 있던 혹은 새로운 연결 리스트에 추가을 해야합니다.
Node 추가 연산 : 연결 리스트의 테일 노드 이에 새로운 노드를 만들어 연결하는 연산
즉 특정 구간에 삽입하는 과정이 아니라, 추가하는 과정이기 때문에 tail뒤에 놔야 합니다.
얘네들의 위계 질서는 오래있던 애들이 최고인가 봅니다!
노드의 추가
void appendNode(Node** head, Node* newNode)
{
//head가 없다면, 추가되는 노드가 head가 된다.
if ((*head) == NULL)
{
*head = newNode;
}
else
{
//테일을 찾아서 newNode에 연결한다.
Node* tail = (*head);
while (tail->nextNode != NULL)
{
tail = tail->nextNode;
}
tail->nextNode = newNode;
}
}처음 매게 변수를 볼까요?
일반적으로 연결 리스트를 사용할 때는, 대부분 첫번째 노드 즉 헤드의 포인터를 이용하여 연결 리스트를 사용하게 됩니다.
왜냐하면 포인터이기 때문에 전체적인 연산을 수행하기 위하여 가장 편리하기 때문이죠!
또한 헤드의 tag 그리고 다음 노드의 tag를 이용하면 모든 노드를 알 수 있기 때문이죠.
따라서 연결 리스트의 본체라고 볼 수 있는 Head와 추가하고자 하는 애기 노드를 매개변수로 받게됩니다.
void appendNode(Node** head, Node* newNode)
{ . . . }
여기서 잠깐 head는 왜 **로 받을까요?
는 밑에서 설명하겠습니다.
제가 아까 Head 노드가 곧 연결 리스트라고 언급을 했습니다.
근데 Head가 없다면? 곧 나의 애기 노드가 첫 노드라면!
이 노드가 Head가 되는 것이 당연하겠죠? 따라서 다음과 같은 코드가 필요하게 됩니다.
//head가 없다면, 추가되는 노드가 head가 된다.
if ((*head) == NULL)
{
*head = newNode;
}그럼 Head가 있다면, 즉 이미 연결 리스트가 형성되어 있다면?
서열 꼴찌니까 Tail의 뒤로 가야할 것 입니다.
해당 노드가 Tail인지는 어떻게 알 수 있을까요?
정답은 tag가 비었다는 것 입니다. 즉 Next Node가 없다는 것!


그림과 같이 이전 노드가 다음 노드를 가리키는 방식입니다.
따라서 tail인지 구분하기 위하여 다음과 같은 코드가 필요합니다.
else
{
//테일을 찾아서 newNode에 연결한다.
Node* tail = (*head);
while (tail->nextNode != NULL)
{
tail = tail->nextNode;
}
//찾았네요 tail의 다음 노드를 애기 노드로 지정합니다.
tail->nextNode = newNode;
}이제 tail은 애기 노드가 되었습니다.
왜냐하면 tag 즉 다음 노드가 없기 때문이죠!
이렇게 추가 과정은 끝이 나게 됩니다.
head는 왜 **로 받을까요?
자동 메모리 스택
자유 메모리 힙
**이 아닌 *를 매개변수로 받는다고 예시를 들겠습니다.
먼저 추가 함수를 호출하는 코드를 다음과 같이 작성합니다.
Node* list = NULL;
Node* newNode = NULL;
newNode = createNode(25);
appendNode(list, newNode);
한눈에 봤을 때, List는 즉 Head, Head는 즉 List라고 말씀 드렸었죠?
따라서 현재 상황은, 연결 리스트가 없는 정말 초기 상태라고 말씀드릴 수 있습니다.
변수를 선언한 코드를 그림으로 확인할 까요?

특정 함수 내에서 선언 하였으니, 프로세스 스택에 쌓여있을 것 입니다.
그리고 createNode를 거치면서 malloc함수에 의해 메모리를 할당받았죠?
할당 받은 그림을 보면 다음과 같습니다.

그리고 나서, apppend 함수를 생각해 봅시다.
동적으로 할당하지 않은 이상, 함수에서 사용하는 변수들은 stack에 생성하는 것은 알고 있을 것 입니다.
append에서 매개변수로 받는 변수들과 stack을 그림으로 보겠습니다.

이 상황에서 append 함수의 과정을 거친다고 생각 해 볼까요?
해당 함수에서는 만약 head가 NULL 이라면 newNode가 head가 된다는 조건문(if)가 있었습니다.
그럼 다음과 같은 그림으로 이어지게 되겠죠?

음! 여기까지는 문제가 없어 보이나요?
그렇다면, append 함수가 끝나면 stack에서 지워지게 되는 것은 알고있죠?
그렇게 된다면 어떨까요?

이런! 함수가 끝나니 다 지워지고 말았습니다.
더 큰 문제는 List가 NULL이라는 문제입니다.
newNode가 List의 Head가 되라는 코드를 수행했지만 List가 없는 초기상태(NULL)로 다시 돌아왔습니다.
따라서 내가 가지고 있는 값이 아닌, 나 포인터의 주소를 줘야한다는 것이 되는거지요.
Node의 탐색 연산
지금까지 노드를 생성하고 추가하는 연산을 진행했습니다.
연결리스트는 자료 구조중 하나이죠?
자료구조란 무엇이겠습니까 데이터를 보관하기까지의 과정과 사용하기 위해 편리한 연산과정의 총체겠죠?
따라서 탐색하는 연산의 코드를 보겠습니다.
Node 탐색 연산 : 노드를 순회하여 임의의 노드를 찾아 반환하는 과정
연결 리스트의 단점 중 하나로, 연결된 노드들을 징검다리 건너듯 순차적으로 순회하며 찾아가야 합니다.

즈으으응ㅇ말 비효율적인 탐색이죠.
똑같이, 2번째 3번째 노드를 가져오라는 명령도 동일하게 작동할 것 입니다.
노드의 탐색
Node* getNodeAt(Node* head, int location)
{
Node* current = head;
while (current != NULL && (--location) >= 0)
{
current = current->nextNode;
}
return current;
}
매개변수를 보면, Head는 계속 말했던 연결 리스트 즉 연결 리스트의 첫 시작인 헤드가 올 것입니다.
location은 임의의 노드 차례입니다.
1번노드 나오세요, 2번노드 나오세요와 같겠죠?
Node* getNodeAt(Node* head, int location)
{ . . . }앞서 말한 것과 같이, head부터 차례대로 location 번째에 있는 노드를 찾을 것 입니다.
따라서 head가 필두로 와야겠죠.
이제 while문을 보면, current 노드가 NULL이 아닐 때. 즉 현재는 head 노드이고 이 노드가 NULL이 아닐 때와 같죠?
--location 즉 -1이 바로 되면서 시작됩니다. location이 1이고 --location이 었다면, 0 >= 0 으로 검사를 했겠죠?
반대로 location--이라면, 1인 상태로 검사를 맡은 후 lcoation은 다음 코드로 넘어 가면서 마이너스가 됩니다.
그런식으로, 임의의 순번 location이 0으로 내려가면서 순번을 찾고있네요.
그림으로 볼까요?

이렇게 순차적으로 간다고 칩시다.

2번 반복했을 땐, 다음과 같네요.
그럼 이제 location이 0이네요! 마지막 결과까지 볼까요?

이렇게 결과를 볼 수 있습니다.
while (current != NULL && (--location) >= 0)
{
current = current->nextNode;
}
return current;Node의 삭제 연산
노드를 삭제도 할 수 있어야겠죠?
단순히 삭제를 하는 것이 아닌 삭제하는 노드가 가리키던 노드를, 삭제 노드 전 노드가 가르켜야 겠죠?
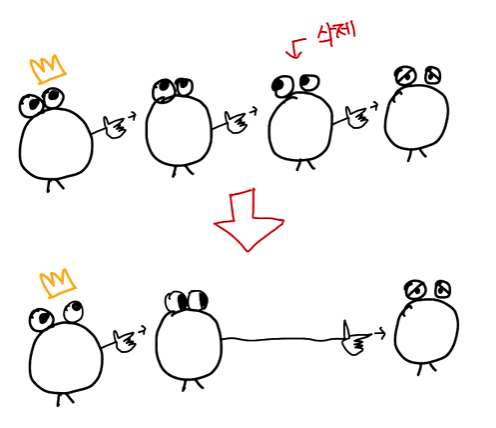
따라서 삭제 연산은 삭제될 노드가 가리키는 다음 노드의 정보를 인수인계하는 과정과 같습니다.
노드 삭제 연산(Tag 인수인계)
void removeNode(Node** head, Node* remove)
{
if ((*head) == remove)
{
*head = remove->nextNode;
}
else
{
Node* current = *head;
while (current != NULL && current->nextNode != remove)
{
current = current->nextNode;
}
if (current != NULL)
{
current->nextNode = remove->nextNode;
}
}
}
매개변수는 이제 이해했죠?
연결 리스트와 삭제할 노드를 전달 받습니다.
void removeNode(Node** head, Node* remove)
{ . . . }
첫번째 조건문(if)를 보면,
head가 지워질 대상이라면? 인겁니다.
그럼 head가 가리키는 다음 노드가 head가 됩니다.

if ((*head) == remove)
{
*head = remove->nextNode;
}else를 보면, while문이 나옵니다.
1. current가 NULL이 아닌경우
2. current의 nextNode가 remove가 아닌경우
즉 찾고있는 노드는 current의 nextNode가 remove인 경우입니다.
왜냐하면 remove가 가리키는 노드를 current가 가리켜야 하거든요.
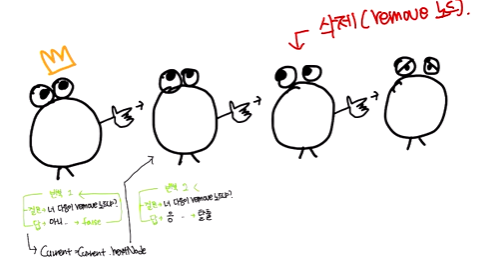
while을 탈출한 이후, remove 노드의 nextNode를 current의 nextNode로 바꿔주며 인수인계가 끝나게 됩니다.
else
{
Node* current = *head;
while (current != NULL && current->nextNode != remove)
{
current = current->nextNode;
}
if (current != NULL)
{
current->nextNode = remove->nextNode;
}
}그 후, 실질적으로 삭제가 되어야 겠죠?
저희는 모든 노드를 동적으로 메모리를 할당받아 생성 해 주었습니다.
그렇기에 free라는 함수를 써서 해제하면 되겠네요.
이전에 만들어 두었던 함수를 사용하면? 오케이네요.
void main()
{
Node* list = NULL;
Node* node2 = NULL;
appendNode(&list, createNode(0));
appendNode(&list, createNode(1));
appendNode(&list, createNode(2));
appendNode(&list, createNode(3));
node2 = getNodeAt(list, 2);
removeNode(&list, node2);
destroyNode(node2);
}
Node의 삽입 연산
Node를 추가하면, tail에 붙였습니다.
그럼 중간에 삽입하는 연산도 필요할거에요.
이전에 삭제했을 때, 가리키는 노드가 누구인지 확실하게 잡아주었죠?
마찬가지로 삽입했을 때 영향을 받는 노드의 nextNode를 수정해야 합니다.
void insertAfter(Node* current, Node* newNode)
{
newNode->nextNode = current->nextNode;
current->nextNode = newNode;
}너무 쉽죠?

newNode의 다음 노드는 current가 가리키고 있던 노드가 되고
current의 다음 노드는 newNode가 됩니다.
이런식의 insert를 사용하기에는 몇번째에 들어가고 싶다는 정보가 필요하게 됩니다.
실질적으로 위의 코드를 사용하기 위하여 다른 함수들이 필요하겠죠?
2번 노드뒤에 새로운 노드를 삽입하기 위하여 작성한 코드입니다.
void main()
{
Node* list = NULL;
Node* node2 = NULL;
appendNode(&list, createNode(0));
appendNode(&list, createNode(1));
appendNode(&list, createNode(2));
appendNode(&list, createNode(3));
node2 = getNodeAt(list, 2); //2번 노드가 어떤 노드 인지
Node* newNode = createNode(20); // 새로 들어갈 노드
insertAfter(node2, newNode);
}Node 개수 세기 연산
이제 노드를 어떻게 부르는지 어떻게 사용하는지 head가 뭘 의미하는지 잘 알았다고 가정하겠습니다.
int getNodeCount(Node* head)
{
int count = 0;
Node* current = head;
while (current != NULL)
{
current = current->nextNode;
count++;
}
return count;
}
쉽죵?
Linked List 예제 프로그램
지금까지 배운 연산을 모두 활용할 수 있는 프로그램을 작성해 보겠습니다.
#include<stdio.h>
#include<stdlib.h>
typedef int elementType;
typedef struct tagNode
{
elementType data;
struct tagNode* nextNode;
} Node;
Node* createNode(elementType newData)
{
Node* newNode = (Node*)malloc(sizeof(Node));
newNode->data = newData;
newNode->nextNode = NULL;
printf("[%d]노드 생성 완료..\n", newNode->data);
return newNode;
}
void appendNode(Node** head, Node* newNode)
{
//head가 없다면, 추가되는 노드가 head가 된다.
if ((*head) == NULL)
{
*head = newNode;
}
else
{
//테일을 찾아서 newNode에 연결한다.
Node* tail = (*head);
while (tail->nextNode != NULL)
{
tail = tail->nextNode;
}
tail->nextNode = newNode;
}
}
void destroyNode(Node* node)
{
printf("[%d]노드 해제 완료..\n", node->data);
free(node);
}
Node* getNodeAt(Node* head, int location)
{
Node* current = head;
while (current != NULL && (--location) >= 0)
{
current = current->nextNode;
}
return current;
}
void removeNode(Node** head, Node* remove)
{
if ((*head) == remove)
{
*head = remove->nextNode;
}
else
{
Node* current = *head;
while (current != NULL && current->nextNode != remove)
{
current = current->nextNode;
}
if (current != NULL)
{
current->nextNode = remove->nextNode;
}
}
}
void insertAfter(Node* current, Node* newNode)
{
newNode->nextNode = current->nextNode;
current->nextNode = newNode;
printf("[%d] -> [%d]\n", current->data, newNode->data);
}
int getNodeCount(Node* head)
{
int count = 0;
Node* current = head;
while (current != NULL)
{
current = current->nextNode;
count++;
}
return count;
}
void printbarr()
{
printf("================================================================\n");
}
void main()
{
Node* list = NULL;
Node* newNode = NULL;
Node* current = NULL;
int count = 0;
printbarr();
printf("연결 리스트의 노드 개수를 입력 해 주세요 : ");
int nodeNum;
scanf("%d", &nodeNum);
//노드 생성
printbarr();
for (int i = 0; i < nodeNum; i++)
{
appendNode(&list, createNode(i+1));
}
//노드 추가
printbarr();
printf("노드 추가 생성 중 입니다..\n");
count = getNodeCount(list);
appendNode(&list, createNode(count + 1));
//노드 중간에 추가
printbarr();
printf("노드를 중간에 삽입 중 입니다..\n");
count = getNodeCount(list);
int mid = 0;
if (count > 1) mid = 1;
Node *midNode = getNodeAt(list, mid);
newNode = createNode(10);
insertAfter(midNode, newNode);
// 노드들 출력
printbarr();
printf("노드를 출력 중 입니다..\n");
count = getNodeCount(list);
for (int i = 0; i < count; i++)
{
current = getNodeAt(list, i);
printf("[%d번째]노드 데이터 : %d\n",i+1, current->data);
}
//노드 제거
printbarr();
printf("노드를 해제 합니다..\n");
count = getNodeCount(list);
for (int i = 0; i <count ; i++)
{
current = getNodeAt(list, 0);
if (current != NULL)
{
removeNode(&list, current);
destroyNode(current);
}
}
}
정신없네 ㅎㅎ...
끝으로
이제 연결리스트를 알아봤는데요, 이게 시작이니.. 하하
백준승생님 문제를 풀다보면 어쩔 수 없이 사용하게 되는 자료구조라 바로바로 휙휙 나올 수 있을 정도로 보면 좋을 것 같아요.
사실 연습하지 않아도 백준을 풀다보면 자연스러워 질 것 이라고 생각합니다.
틀린 점이 있다면 알려주세요
이해 안가는 부분이 있다면 장문으로 물어도 좋으니 언제든 물어봐주시길 바랍니다.
참고
이것이 자료구조 알고리즘이다 with C언어
'자료구조' 카테고리의 다른 글
| 후위 표기법 변환, 다익스트라(Dijkstra) 알고리즘, c언어 구현 코드, postfix, infix 계산기, 자료구조 (0) | 2024.11.20 |
|---|---|
| 스택(Stack), c언어 구현 코드, 연결 리스트 기반 스택, 자료구조 (0) | 2024.11.18 |
| 스택(Stack), c언어 구현 코드, 배열 기반 스택, 자료구조 (0) | 2024.11.18 |
| 환형 연결 리스트(Circular Licked List), 원형 연결 리스트, C언어 구현, 코드 부에궹ㄱ (1) | 2024.11.17 |
| 이중 연결 리스트(Double Linked List), C언어 구현, 코드 (0) | 2024.11.17 |



